Human-centered Action recognition and Prediction
Stanford Investigators
TRI Investigators
Project Summary
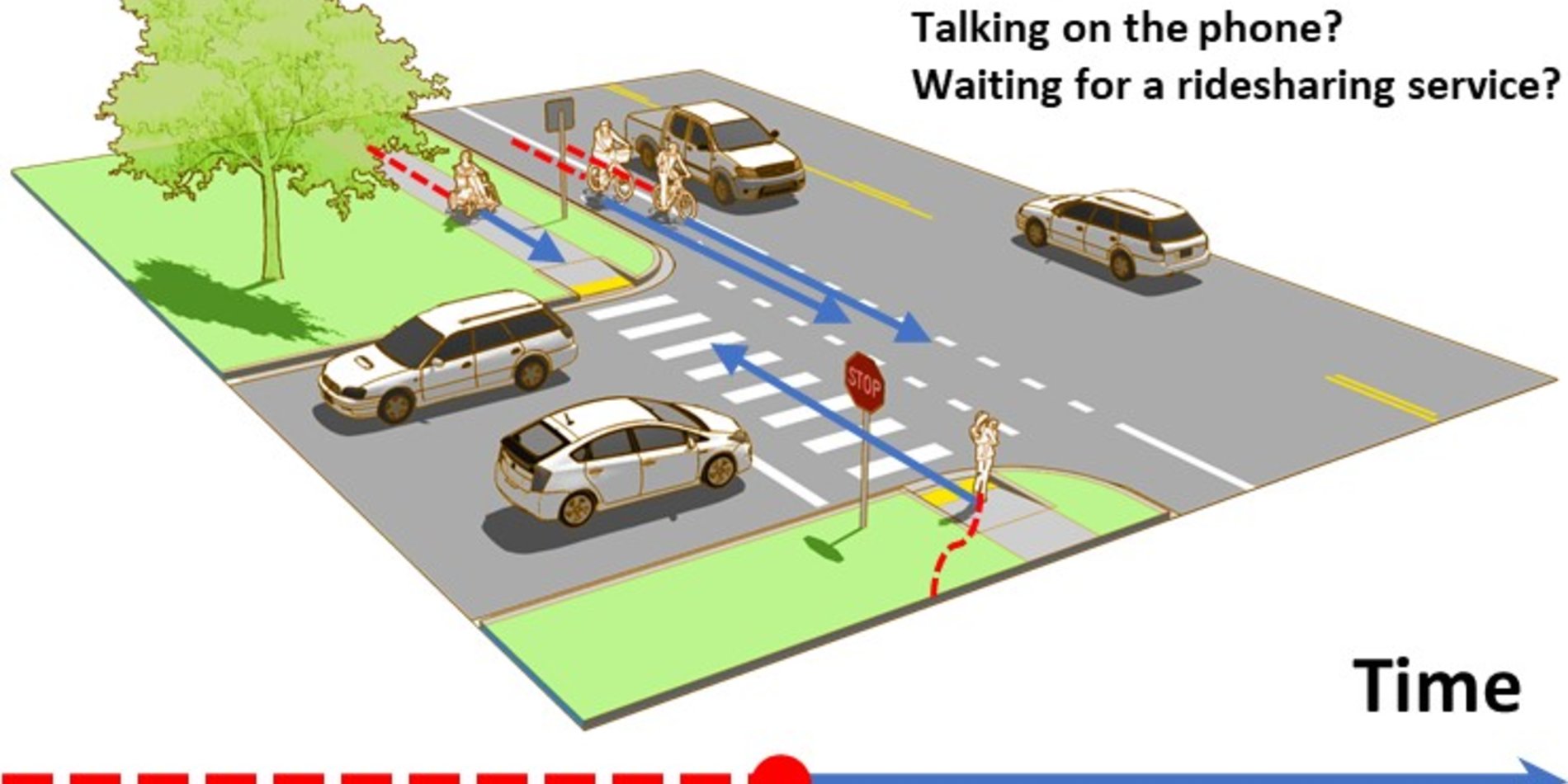
The goal of this project is to efficiently learn representations of rich human behaviors in driving scenes for pedestrian and crowd action recognition and anticipation. To this end, the project team will build upon a set of people-centric hypotheses, some initially explored with TRI, including behavior modeling, interplay between traffic agents, and natural language. They break the project down into five tasks.
In this collaboration, we focus on --
-
Leveraging priors from behavioral sciences for auto-labeling: We will train perception models that can leverage the vast amount of unlabeled video data and auto-annotate the data post-hoc.
-
Leveraging high-level semantic priors for semi-supervised learning: We will work on visual genome and action genome, to model the complex semantics and interactions among objects, pedestrians, and the environment.
-
Temporal reasoning for action prediction: We will develop models that provide multiple possible future outcomes for pedestrian actions. To this end, we will leverage data sets with sequences of actions, such as instructional videos.
-
Efficient and robust training: In parallel to the previous tasks, continuing our collaboration with TRI Co-Is, we will design sample-efficient methods robust to various types of domain shifts (e.g., US to Japan, sim to real) and dataset imbalance and will apply them in all previous tasks.